Machine Learning: Trying to predict a numerical value
This post is part of a series introducing Algorithm Explorer: a framework for exploring which data science methods relate to your business needs.
The introductory post “Machine Learning: Where to begin…” can be found here and Algorithm Explorer here
If you’re looking to use machine learning to solve a business problem requiring you to predict a numerical value, you should look to Regression Techniques.
Regression Techniques
Regression algorithms are machine learning techniques for predicting continuous numerical values. They are supervised learning tasks which means they require labelled training examples.
Use-Cases
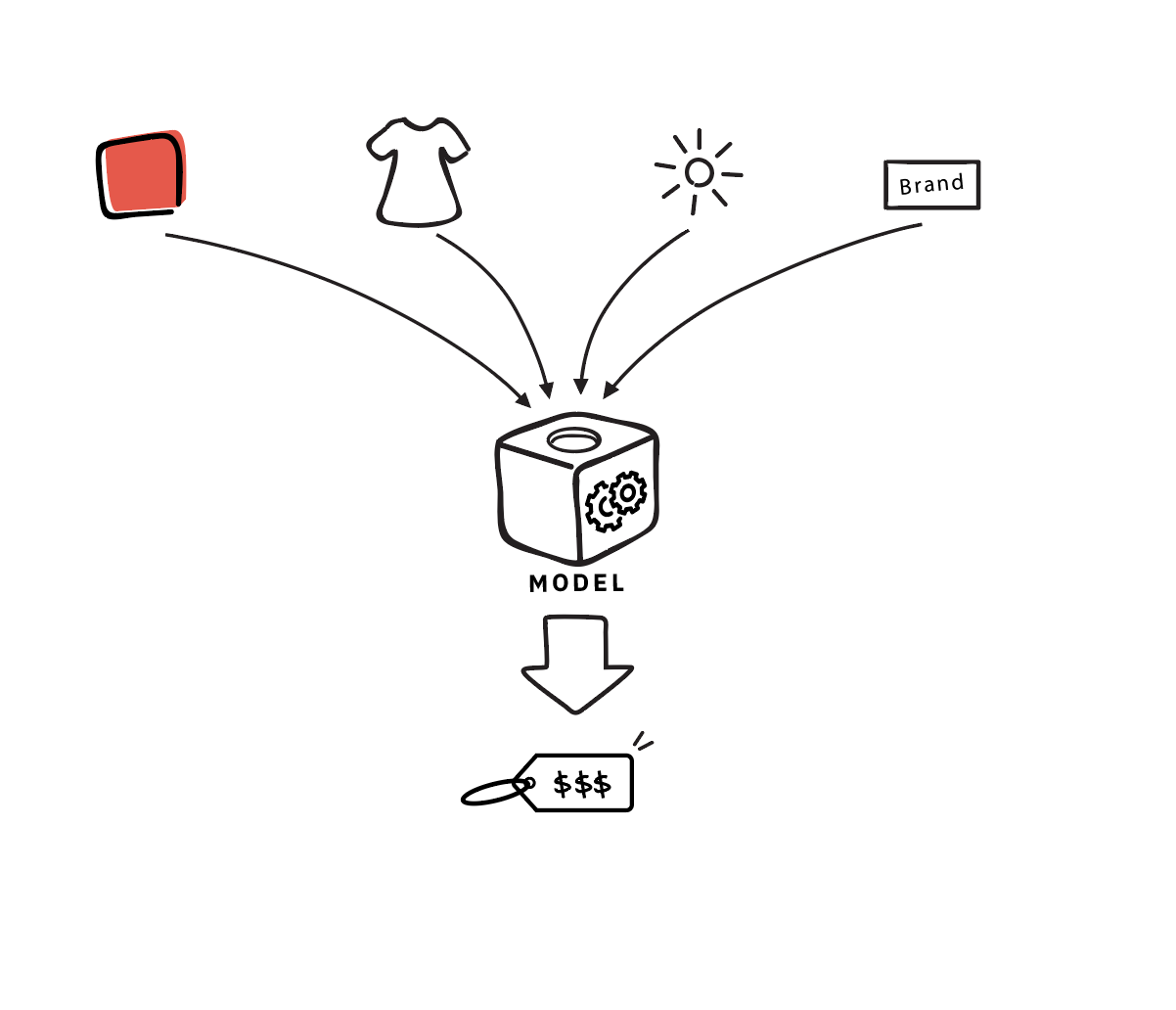
- Predicting the appropriate price for a product based upon size, brand, and location
- Predicting the number of sales each day based upon store location, public holidays, day of the week, and the closest competitor
Most Common Regression Algorithms
Below are introductions on the most common algorithms for predicting a numerical value: Linear Regression, Decision Trees, Neural Networks, and K-Nearest Neighbors
Linear Regression
Linear regression attempts to fit a straight hyperplane to your dataset that is closest to all data points. It is most suitable when there are linear relationships between the variables in the dataset.
Pros
- Quick to compute and can be updated easily with new data
- Relatively easy to understand and explain
Regularization techniques can be used to prevent overfitting
Cons
- Unable to learn complex relationships
- Difficult to capture non-linear relationships (without first transforming data which can be complicated)
Vocabulary
hyperplane — A hyperplane in a 1-dimensional (1D) space is a point. In a 2-dimensional (2D) space, it is a line. A hyperplane in 3-dimensional (3D) space is a plane, a flat surface. To generalize for any dimension, the concept is referred to as a hyperplane.
linear relationships — A relationship is linear if a change in the first variable corresponds to a constant change in the second variable.
Overfitting — An overfit model will have very high accuracy on the training data, having discovered useful features that are specific in the data it has seen. However, it will have low accuracy on test data as it cannot generalize.
non-linear relationships— A non-linear relationship means that the a change in the first variable doesn’t necessarily correspond with a constant change in the second. However, they may impact each other but it appears to be predictable.
Example Python Notebook
Predicting Yacht Resistance with Linear Regression
Decision Trees
Decision trees learn how to best split the dataset into separate branches, allowing it to learn non-linear relationships.
Random Forests (RF) and Gradient Boosted Trees (GBT) are two algorithms that build many individual trees, pooling their predictions. As they use a collection of results to make a final decision, they are referred to as “Ensemble techniques”.
Pros
- A single decision tree is fast to train
- Robust to noise and missing values
- RF performs very well “out-of-the-box”
Cons
- Single decision trees are prone to overfitting (which is where ensembles come in!)
- Complex trees are hard to interpret
Vocabulary
non-linear relationships — A non-linear relationship means that the a change in the first variable doesn’t necessarily correspond with a constant change in the second. However, they may impact each other but it appears to be predictable.
Pooling — This is a way to combine data and is usually done by taking the mean average.
Noise — Noise refers to data points are incorrect which may resulting in discovering patterns that are untrue. These are usually identified if they are outliers, which means they are much different to the rest of the data set. However, be cautious as some outliers may be valid data points and worth investigating.
Overfitting — An overfit model will have very high accuracy on the training data, having discovered useful features that are specific in the data it has seen. However, it will have low accuracy on test data as it cannot generalize.
Example Python Notebook
Predicting Yacht Resistance with Decision Trees & Random Forest
Neural Networks
Neural networks can learn complex patterns using layers of neurons which mathematically transform the data. The layers between the input and output are referred to as “hidden layers”. A neural network can learn relationships between the features that other algorithms cannot easily discover.
Pros
- Extremely powerful/state-of-the-art for many domains (e.g. computer vision, speech recognition)
- Can learn even very complex relationships
- Hidden layers reduce need for feature engineering (less need to understand underlying data)
Cons
- Require a very large amount of data!
- Prone to overfitting
- Long training time
- Requires significant computing power for large datasets (computationally expensive)
- Model is a “black box”, unexplainable
Vocabulary
Neurons — An artificial neuron is a mathematical function. It takes one or more inputs that are multiplied by values called ‘weights’ and added together. This value is then passed to a non-linear function, referred to as an ‘activation function’, which becomes the output.
Input — The features are passed as inputs, e.g. size, brand, location, etc.
Output — This is the target variable, the thing we are trying to predict, e.g. the price of an item.
Hidden layers — These are a number of neurons which mathematically transform the data. They are referred to as ‘hidden’ as the user is only concerned with the input layers, where the features are passed, and the output layers, where the prediction is made.
Feature engineering — Feature engineering is the process of transforming the raw data into something more meaningful, this usually involves working with someone that has domain expertise.
Overfitting — An overfit model will have very high accuracy on the training data, having discovered useful features that are specific in the data it has seen. However, it will have low accuracy on test data as it cannot generalize.
Model — Machine learning algorithms create a model after training, this is a mathematical function that can then be used to take a new observation and calculates an appropriate prediction.
Example Python Notebook
Predicting Yacht Resistance with Neural Networks
K-Nearest Neighbors
K-Nearest Neighbors (KNN) makes a prediction for a new observation by searching for the most similar training observations and pooling their values
Pros
- Simple
- Powerful
- No training involved
Cons
- Expensive & slow to predict new instances
- Performs poorly on high dimensional datasets
Vocabulary
Observation — An observation is a single example, a data point or row in the data.
Pooling — This is a way to combine data and is usually done by taking the mean average.
High dimensional — High dimensional data means that the data has a very large number of features. If your data is represented in a CSV, database or Excel file, if there are a lot of columns which you will be using to build a model with, it’s high dimensional
Example Python Notebook
Predicting Yacht Resistance with K Nearest Neighbors
Further Reading
This series continues with:
- Machine Learning: Where to begin…
- Machine Learning: Trying to classify your data
- Machine Learning: Trying to discover structure in your data
- Machine Learning: Trying to make recommendations
- Machine Learning: Trying to detect outliers or unusual behavior
Many Thanks
I wish to thank Sam Rose for his great front end development work (and patience!), converting my raw idea into something much more consumable, streamlined and aesthetically pleasing.
Similarly, my drawing skills leave much to be desired so thank you to Mary Kim for adding an artistic flare to this work!
